| 后台-系统设置-扩展变量-手机广告位-内容正文顶部 |
一年前,Hugging Face上的模型数量不过几千;而现在这一数字早已突破百万。Hugging Face模型数量的暴增只是AI市场极速发展的一个缩影,但在供需两旺的市场背后,日臻成熟的市场和用户的确在以全新视角审视计算和整个基础架构。
而在这一过程中,AMD也在构建全新的计算和产品版图。
CPU、GPU、网络一样不少!数据中心里的AMD越来越多

美国时间10月10日,AMD在Advancing AI 2024峰会上一口气发布了面向服务器产品的第五代EPYC系列处理器、针对AI和科学计算市场的Instinct MI 325X系列GPU,以及应用于数据中心网络领域的Pensando第三代P4引擎等众多产品。由此,AMD在数据中心领域已经完成了CPU+GPU+先进网络的产品布局,而这些产品正是当下用户在云计算、AI和科学计算等领域的新“三大件”。同时,在与数据中心市场对手真贱麦芒的竞争中,AMD也真正做到了技术先进和产品线完整。
通过CPU+GPU+网络的产品组合,数据中心用户不仅能获得更强的算力、更高的密度和更好的能效,也能借助相互优化的技术栈和完整性颇高的技术生态来获得更好的性能及应用效果,继而在日新月异的AI时代保持领先,并走上一条可持续、可演进的未来发展发展路径。
显然,这正是AMD在数据中心领域中想要实现的1+1+1>3效果。
有看点,更有期待!细看AMD数据中心新品
由于有CPU、GPU、网络等多条产品线的新品助阵,本届Advancing AI峰会的看点也相当丰富。
01、3nm+192核,第五代EPYC再次卫冕“核”战冠军
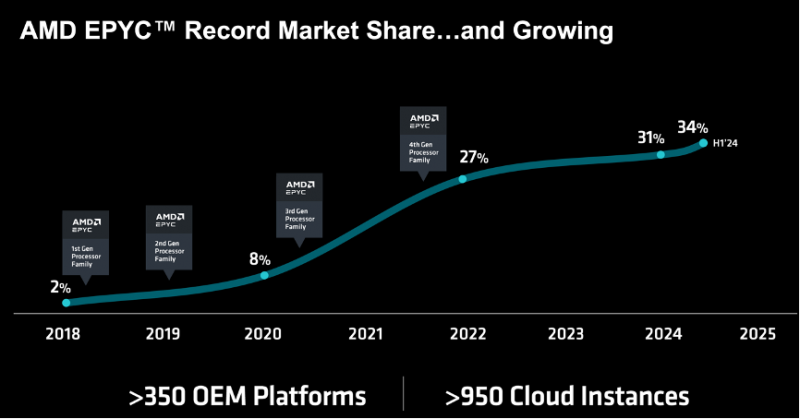
从2017年发布第一代EPYC处理器开始,凭借更多的核心数量、计算密度和整体性能,EPYC处理器的市占率就呈现快速增长趋势。截止2024年H1,AMD在数据中心市场的营收占比已达34%。而350+ OEM伙伴和950+云用户也意味着,EPYC计算平台已成为当今数据中心和云服务市场不可忽视的方案选择。

AMD董事会主席及首席执行官苏姿丰(Lisa Su)博士在峰会现场展示第五代EPYC处理器

第五代EPYC处理器将以9005系列命名,核心代号Turin。新处理将包含4nm制程的Zen 5和3nm制程的Zen 5c两种CPU设计;其中Zen 5核心主打高性能的Scale-Up市场,而Zen 5c核心则针对高密度的Scale-Out市场。
第五代EPYC处理器将继续沿用SP5接口,能够保护用户和OEM伙伴的过往投资,减少平台的制造和购置成本。
第五代EPYC处理器依旧使用Chiplet技术打造,CPU基板上包含负责通讯的IO die(6nm制程)和容纳核心及缓存的CCD die。处理器将提供最高12组DDR5 6400内存通道(24个DIMM插槽,单socket最高可支持6TB内存)和最高128个PCI-E 5.0/CXL 2.0通道(双路系统最高可提供160个PCI-E 5.0通道),最高频率将达到5GHz,支持AVX-512指令集。
而在安全层面,第五代EPYC将支持PCIe link encryption、Trusted I/O技术,以及最新的FIPS 140-3加密认证。多种技术综合应用将允许用户打造全链路的数据加密计算环境,使数据在由CPU、GPU、网卡等设备构成的基础架构链路中始终处于加密状态,并最终实现“数据可用不可见”的安全效果,从根源杜绝数据泄露所带来的危害。
Zen5核心单个CCD包含8个物理核心(N4X制程),支持SMT超线程技术,每核心包含80KB一级缓存(32KB指令缓存+48KB数据缓存,Zen4为32KB+32KB设计)、1MB二级缓存以及一个总容量为32MB的共享式三级缓存。
规格最高的EPYC 9755处理器将包含16个Zen5 CCD,提供128个物理核心、256个线程和总计512MB的三级缓存;处理器基础频率2.7GHz,Boost频率4.1GHz,TDP为500W。
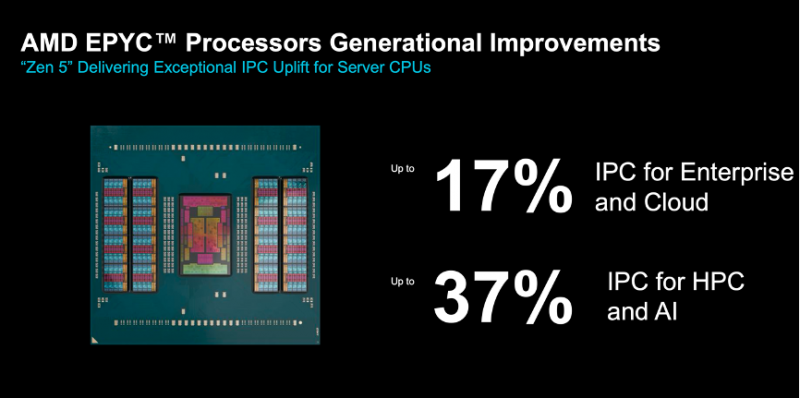
使用Zen5核心的EPYC 9005系列处理器将为用户带来最高17%的IPC性能提升和37%的HPC及AI业务性能提升。

性能对比对象为64核心的Xeon Platinum 8592+
Zen 5c核心单个CCD将包含16个物理核心(N3E制程),同样支持SMT超线程技术,每个CCD的共享式L3缓存数量同样为32MB。
192核、384线程的PEYC 9965处理器将包含12个CCD,提供384MB三级缓存;处理器基础频率2.25GHz,Boost频率3.7GHz,TDP同为500W。
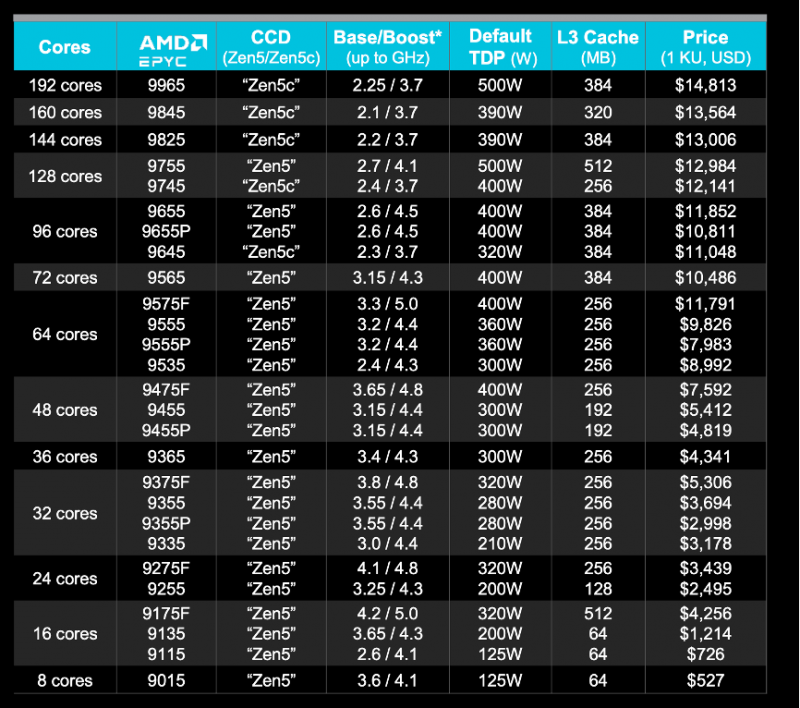
EPYC 9005处理器产品序列
在针对传统应用的Scale-Up市场,使用Zen5核心的第五代EPYC 9005系列处理器在相同的500W功耗下,带来了更多的三级缓存、更高的基频和Boost频率、更多的PCI-E 5.0/CXL 2.0通道数量以及更大的内存容量支持。而在针对云环境的Scale-Out市场,使用Zen5c核心的第五代EPYC 9005系列处理器则能带来大幅领先的核心数量和计算密度,进一步提升CSP的服务能力并降低基础架构TCO。
发布会现场,AMD董事会主席及首席执行官苏姿丰博士也邀请到了来自Meta的高管分享EPYC系列处理器的使用经验。Meta高管表示,目前公司已经使用了超过150万颗EPYC系列处理器。EPYC系列处理器不仅提供了极致的性能和多样化的功能,也用更高的计算密度和能效帮助Meta降低了基础架构的TCO。
在基础规格的明显优势与优惠价格的加持下,AMD将有望延续过去数年积累的增长势头,在进一步抬升市占率的同时为用户带来成本和性能收益。
02、288G HBM3e+算力提升,Instinct MI325X直击AI行业痛点
虽然当下AI市场需求持续火爆,但在多数AI推理和训练应用中,GPU集群的平均负载远没有达到满载;相反,显存容量则成为了主要的掣肘因素。换言之,推动用户购买更多GPU的原因不是算力的稀缺,而是显存容量的不足。而针对这一矛盾,AMD在Advancing AI峰会上发布的Instinct MI325X GPU则给予了正面回应。

Instinct MI325X仍将采用CDNA3架构,提供256GB HBM3e显存以及6TB/s的显存带宽,而这也将MI325X的FP8性能推至2.6PFlops,而FP16性能也将达到1.3Pflops。相对于竞争对手的192GB HBM3e、96GB HBM3等配置,这样的配置无疑更有诚意、也更有竞争力。
一台典型的8卡Instinct MI325X计算平台将提供2TB HBM3e显存、48TB/s显存带宽,896GB/s Infinity Fabric(节点内GPU互联)联接带宽;而性能也将达到20.8PFlops的FP8和10.4PFlops的FP16。换言之,相对于8个H200组成的计算节点,8卡MI325X平台将提供1.8倍的显存容量、1.3倍的显存带宽和1.3倍的FP16/8性能。在AMD进行的Llama 3.1 405B大模型推理测试中,8卡MI325X平台的性能将达到H200 HGX平台的1.4倍,而70B大模型的性能表现也将达到H200 HGX平台的1.2倍。
此外,AMD也在峰会现场预告了2025年H2即将发布的Instinct MI350系列GPU产品。相对于MI325X,MI350系列将升级至3nm工艺和CDNA4架构,并提供对FP4和FP6数据类型的支持;在进一步提升计算效率的同时,MI350X也会将显存容量继续推高至288GB HBM3e。
新加入的FP4和FP6数据格式将有助于继续压缩模型体积,帮助用户实现模型体积、显存消耗与训练效果之间的平衡。
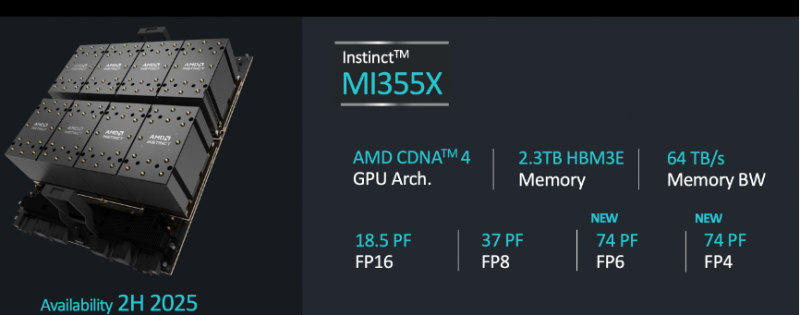
而在性能方面,旗舰的Instinct MI355X的288GB HBM3e显存将提供8TB/s的带宽,和4.6/2.3PFlops的FP8/16性能。而在新加入的FP4和FP6数据格式下,MI355X的性能则会达到惊人的9.2PFlops(FP4和FP6性能相同)。
当8张MI355X组成计算平台,对应的性能也将来到18.5PFlops FP16、37PFlops FP8、74PFlops FP6/4。
03、更多功能、更高效率,Pensando P4引擎
自从2022年收购Pensando之后,AMD已经推出了2代P4网络引擎。其不仅能以智能网卡形态存在于计算节点之中,更能应用在TOR交换机领域,实现集中化的流量管理和安全功能。而伴随AI负载成为现代数据中心的主要业务之一,网络架构也在加速演进。
在服务器层面,用户需要带宽更高、算力更强的智能网卡来充当DPU,以实现SDN功能、数据加密、防火墙等功能;而在GPU集群内部,用户也需要更强大的网络来构建高带宽、低延迟的GPU互联。前者成为Front-end网络,而后者则推动了Back-end需求。

而在Advancing AI峰会上,AMD推出的第三代P4网络引擎则能同时满足Front-end和Back-end网络需求。
新一代P4网络引擎延续了P4架构完全可编程的优势,并将吞吐量提升至120M Packets/s,端口带宽也来到了400G;而在SDN、安全、存储等领域,新引擎的处理能力则来到了500万联接每秒。
在产品层面,新的P4网络引擎会以两种形态呈现,即面向Front-end网络的AMD Pensando Salina 400,和面向Back-end网络的AMD Pensando Pollara 400。

作为智能网卡或者DPU,Salina 400能够实现SDN、防火墙、数据加密、负载均能、NAT等多种功能,继而卸载CPU的网络负载,让更宝贵的CPU算力能够更多的用于生产和业务。Salina 400在提供上述功能的同时,能够提供2个400G以太网端口,让数据中心适配未来的800G网络架构。

而Pollara 400则是专门面向GPU互联的网卡产品,也是全球首款支持Ultr Ethernet标准的网卡产品。通过第三代P4引擎内的可编程硬件管线,Pollara 400可实现GPU RDMA流量的完全可编程,由此,GPU集群便可以太网技术堆栈之下,解决高负载所带来的网络拥塞和丢包,从而提升GPU集群的整体计算效率。
根据以往经验,1%的网络丢包将使集群性能降低50%,2%的丢包则会让集群陷入瘫痪。而在AI应用中,为避免以太网(RoCE)网络拥塞和宕机所带来的损失,用户通常需要花费30%的时间来创建额外CheckPoint及重新载入数据;显然,这意味着大量GPU时间的浪费。而在使用Pollara 400时,用户则能继续享受以太网技术栈所带来的开放和低成本优势,又能避免网络拥塞和丢包,真正实现鱼与熊掌的兼得。

AMD表示,在与RoCE v2标准的对比中,UEC Ready的Pollara 400在消息完成时间、集体通讯完成时间方面分别有着6倍和5倍的性能优势;配合更高的端口带宽,通讯效率的大幅提升意味着更低的传输延迟和更少的网络拥塞。
作为AMD Pensando系列产品的用户,微软Azure高管表示:Pensando DPU可卸载大量CPU负载,为Azure每年节省1亿+美元的成本。而IBM Cloud高管也表示:目前,IBM Cloud已将Pensando DPU作为云主机的默认选项之一提供给用户,以提升客户业务的整体效率。
Front-end与Back-end网络的双端创新不仅让AMD网络产品有着极高的用户价值,更从侧面提升了AMD CPU和GPU解决方案的吸引力。而CPU+GPU+高效网络的组合也让用户更有信心使用AMD的数据中心产品。
AI改变世界,AMD改变计算
AI是生产力的催化剂,在创造新需求的基础上,也为企业的生产经营带来了深刻的变革。而在用户真正拥抱AI所带来的变革和收益之前,算力已成为一道必须跨过的门槛。无论是通过云服务还是自有基础架构来满足需求,算力的高低和效率都将成为用户决胜当下与未来的关键指标。
而AMD则用CPU、GPU和网络产品的组合为用户提供了全新选择,让用户能够在绝对性能、成本、能效、密度等众多因素之间取得新的平衡。这是AMD产品在最近数年间广受数据中心用户欢迎的基础,也是AMD继续前行的底层动力。

如果说AI正在改变世界,那么AMD则在用全新的计算产品来驱动AI和未来。走出AMD Advancing AI 2024的会场,我们的确有理由期待一个更美好的数字未来。
内容来自:太平洋电脑网



