| 后台-系统设置-扩展变量-手机广告位-内容正文顶部 |
沿着大模型的“原材料”脉络向上追溯,我们能在AI数据供应链的版图中,发现一家名为艺恩的公司。
2026年3月的一个周四凌晨,北京中关村某大模型厂商的会议室里,气氛凝重。几位数据负责人围坐在桌前,展开一场艰难的讨论。桌上摊开的Excel表格,左边一栏是“预训练语料清单”,右边是“来源备注”。此次会议的核心任务简单却棘手——剔除“来源不清”的语料,并寻找合适的替代品。这已是该公司半年内第四次开展此类工作。一位参会者事后感慨:“这就像给一艘已经下水的船换龙骨,也可以说是版权清洗。”
这并非个例。从旧金山的Market Street到北京的望京,从伦敦高等法院到慕尼黑地方法院,全球AI厂商都在为同一件事忧心:训练模型的数据是否干净、来源是否清晰、供应能否持续。也是在这一年,一条长期隐于幕后的产业链——AI数据供应链,被资本市场和产业记者推到了聚光灯下。Scale AI被Meta以143亿美元高价收购;Surge AI传出250亿美元的惊人估值;Mercor在一年内估值从20亿飙升至100亿美元;而在中国,海天瑞声2025年上半年营收同比增长约七成,新三板上的艺恩数据也交出了一份亮眼成绩单:2025年营收3735.54万元,同比增长49.86%,数据产品业务收入同比增长127.68%,无形资产(数据资源)同比增长103.34%,海外业务更是首次实现千万级订单突破。
一位长期跟踪AI基础设施的PE合伙人直言:“大模型的竞争,最终是数据的竞争;而数据的竞争,关键在于供应链的竞争。”
本文将沿着大模型的“原材料”脉络,深入拆解这条供应链的五层结构,绘制全球与中国的对标图谱,并探寻艺恩公司在这张拼图中的具体坐标。
一、AI数据供应链的五层结构:从“原矿”到“菜肴”
若将大模型比作一家餐厅,算力是火,模型架构是菜谱,调参是火候,那么数据便是食材。而食材从田间到餐桌,需历经五道关卡。
第一层是“采集层”,如同食材的“田间”。这里汇聚了原始数据的持有者,包括视频与图文平台(如抖音、B站、YouTube、X)、版权方(出版社、影视公司、音乐公司)、公开数据抓取方以及合规的数据经纪商。这一层的核心问题是“谁拥有原始权利”。Anthropic曾从LibGen这类影子图书馆下载数百万册图书,2025年8月,该案以15亿美元现金和解,平均每部作品约3000美元,这一数字在2026年重新定义了“原矿”的采购底价。
第二层是“清洗层”,对应“洗菜切菜”。数据标注工厂、结构化工具、去重与去毒管线集中于此。海外有Scale AI、Surge AI、Mercor、Labelbox、Snorkel AI、Turing、Invisible Tech等标志性企业;国内则有海天瑞声、云测数据、百度智能云数据众包、字节火山引擎数据服务、数据堂、星尘数据等。2025年,Surge AI年化营收达14亿美元;Mercor单日支付给3万名合约工的费用超过150万美元;Snorkel提出的“Expert Data-as-a-Service”概念,将标注从“按件计酬”推向“按专家小时计酬”。
第三层是“产品层”,如同“成菜”。这里的玩家不再局限于出售劳动力,而是将数据打包成“数据集/智库/订阅产品”对外交付。产品形式多样,既有通用语料包,也有垂直数据集,涵盖影视综、医疗、法律、金融、电商、代言人、社媒情绪、投流素材等领域。艺恩数据的enbase数据智库、艺恩营销智库便处于这一层。
第四层是“渠道层”,对应“配送”。数据交易所(上海、北京、深圳、贵阳数据交易所)、API分发平台、IP授权平台以及面向海外客户的合规出口通道构成了这一层的基础设施。随着数据资产入表自2024年1月正式执行,这一层发生了会计层面的重大变革——数据首次成为可被“记录”的资产。
第五层是“应用层”,如同“厨师”。大模型厂商、互联网巨头AI业务线、出海平台、垂直Agent创业公司是这一层的买家。他们使用数据,也为数据“投票”。谁的数据能让模型的某项指标提升,能让一个Agent的转化率增加几个百分点,谁就能赢得下一个订单。
这条供应链最反直觉之处在于:价值并非集中在最上游。原始数据拥有者未必盈利(平台方面临反爬困扰,版权方常陷入诉讼纠纷),清洗工厂利润率也不高(依赖大量人力),真正获得高毛利、高议价权和高估值的,是第三层产品层与第四层渠道层的复合卡位者。他们将原料加工成“标准菜”,以订阅或授权的方式出售。Surge AI毛利率超过50%且已盈利,Scale AI在Meta入股前营收达8.7亿美元并持续增长,艺恩数据2025年毛利率达48.79%,这三个数字揭示了同一产业规律。
二、五个痛点:供应链上的五道暗流
在产业链的每一层,都隐藏着一个难以回避的问题。
采集层面临“数据孤岛+版权不清”的困境。一位头部大模型厂商的数据负责人透露:“近两年的数据采购清单中,真正能拿出授权合同的仅约七成。剩下三成,我们既不敢放心使用,又不敢完全舍弃。”Bartz v. Anthropic案以15亿美元和解后,这三成数据从“便宜”变为“昂贵”,因为一旦被起诉,单部作品的赔偿中位线就是3000美元。
清洗层存在“质量波动+多模态对齐困难”的问题。RLHF数据对标注员的学历、专业和语言能力要求日益严苛,Mercor上挂单的医生、律师、PhD时薪从100美元起跳;视频 - 文本对齐、物理一致性、音视频同步等多模态任务,使旧式的“一图一标签”标注流水线彻底过时。
产品层面临“垂直深度不足+通用与垂类失衡”的挑战。过去两年,通用语料供给过剩,垂类语料供给稀缺,形成一种奇特现象:大模型规模不断扩大,但垂直场景的表现却常常不升反降。Epoch AI预测,高质量公开通用文本可能在2027年前耗尽,而垂类高质量数据还远未得到充分开发。
渠道层存在“交易机制不成熟+跨境合规”的问题。国内四家数据交易所成立多年,但实际成交量仍低于预期;数据资产入表虽写入会计准则,但定价、审计、交易撮合、国际互认等问题仍有待解决。跨境方面,2025 - 2026年,中国数据出海和海外数据入华面临新的监管迷宫。
应用层则面临“采购缺乏基准+效果难量化+复购依赖信任”的难题。一位互联网巨头的AI业务线PM无奈表示:“我们购买数据最痛苦的不是价格高,而是不知道买得是否正确。”模型训练具有典型的“滞后反馈”特点,今天购买的数据要到下一个版本才能知道是否有效,而下一个版本又存在诸多无法控制的变量。
五层结构,五个痛点,供应链上的每一层都在寻求秩序。这也是为何这个过去被视为“苦活累活”的领域,在2025 - 2026年突然爆发出产业级别的估值张力。
三、艺恩在这张图上的坐标:三层复合卡位者
将艺恩数据置于产业链图中,其位置十分清晰:它是横跨产品层、渠道层与部分应用层的复合卡位者。
艺恩数据并非海天瑞声那样的“通用语料工厂”,不依赖人海战术进行标注交付;也不像猫眼、灯塔等依托票务流水的“平台派”,没有天然的一方数据闭环;更不是一家纯粹的咨询公司。它更接近海外Snorkel AI所描述的“Expert Data-as-a-Service”模式——将行业专家积累和多年沉淀的结构化数据资产,打包成订阅化、标准化的产品对外销售。
艺恩的资产基本盘可概括为:视频 + 图像 + 文本三大模态,覆盖影视综 + 社媒 + 电商 + 版权四大行业领域。产品方面,enbase数据智库面向专业使用者,艺恩营销智库面向品牌与代理商。这套产品矩阵在AI数据供应链中的独特之处在于,它没有在“通用语料的红海”中拼量,而是在“垂类高质量结构化数据的蓝海”中抢占先机。
2025年的财务表现,从市场角度验证了这一坐标。营收3735.54万元,同比增长49.86%,毛利率48.79%,净利润363.55万元。这些数字在整个AI数据赛道中或许不算突出,但其中几个结构性信号值得关注:
其一,数据产品业务收入同比增长127.68%,且毛利率同比上升16.83个百分点。这表明艺恩从“卖咨询 + 项目”向“卖产品 + 订阅”的转型,在数量和质量上均取得进展。对比海外同行,Surge AI的增长曲线也是产品化曲线,Snorkel AI D轮估值13亿美元,同样得益于“数据即产品”的订阅叙事。
其二,无形资产(数据资源)同比增长103.34%。这是数据资产入表落地后的账本调整,也是一种“资产化”信号。当一家数据公司开始在资产负债表上将数据列为无形资产,意味着它正以资产而非服务的方式定义自身产业价值。
其三,海外业务首次实现千万级订单突破。Scale AI因Meta入股失去Google、OpenAI、xAI等关键客户后,留下的市场真空正被Surge AI、Mercor和中国的AI数据公司填补。这并非艺恩一家公司的机遇,海天瑞声2025年上半年在中国香港、新加坡、美国设立子公司,并购菲律宾交付基地,中国AI数据出海正开启一条全新赛道。
从可替代性角度看,艺恩的通用咨询能力和项目化定制能力可被替代,但在中国影视综、代言人、剧综软广、社媒声量等细分垂类领域,其长达十余年的结构化资产积累,形成了一条难以在短时间内复制的护城河。当然,艺恩也面临一些风险,如体量较小、客户集中度较高、产品化比例仍在提升阶段,但这些都是处于“拐点之上”的公司的真实写照。
四、海外对标:给中国AI数据公司一面估值镜子
将艺恩置于全球坐标系中,一些有趣的现象浮现。
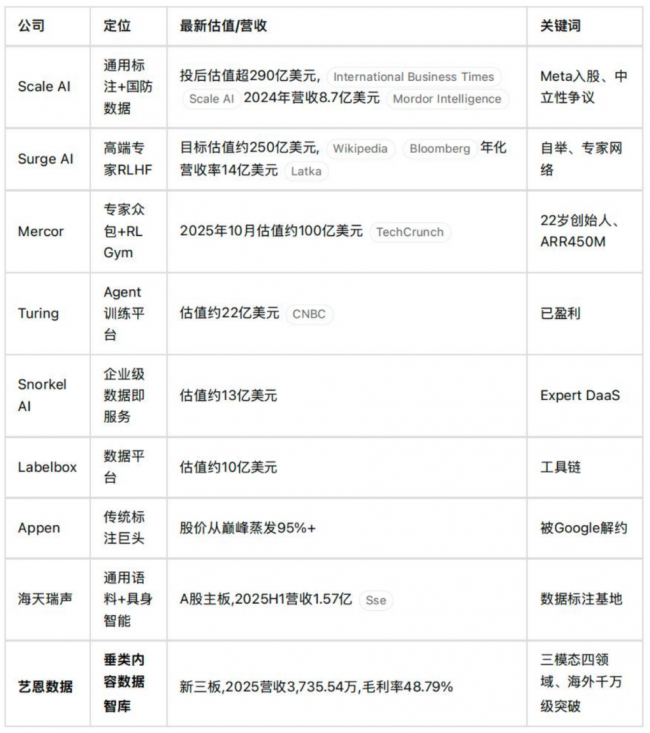
两个重要观察值得强调:其一,高估值属于“产品化 + 专家化 + 资产化”的复合型玩家,而非单纯的人力密集型标注厂;其二,Scale AI的中立性危机,为中国AI数据公司打开了一个原本不存在的海外窗口。
2026年初,Anthropic以1830亿美元估值完成约130亿美元新融资,AWS累计加注至250亿美元;OpenAI以8400亿美元估值完成1100亿美元融资。下游资金端的充裕,直接提升了上游数据端的采购能力。Surge AI年化营收冲至14亿美元、Mercor ARR突破4.5亿美元、Snorkel引入Expert DaaS产品线,背后都是这股资金浪潮的推动。中国AI数据公司也不会置身事外。
五、三个结构性机会和一个必须克制的判断
站在2026年第二季度的观察点,中国AI数据供应链存在三个结构性机会。
第一个机会是数据资产入表带来的“资产化红利”。财政部《企业数据资源相关会计处理暂行规定》自2024年1月起实施,数据首次作为无形资产或存货进入资产负债表。艺恩无形资产(数据资源)同比增长103.34%,这不仅是一个会计动作,更是估值逻辑的切换——从“卖服务赚收入”转向“攒资产赚资产溢价”。当数据资产可被审计、评估和质押,这条产业链的金融属性将被重新发掘。
第二个机会是中国AI出海带来的“合规数据出境通道”机遇。2025 - 2026年,中国短剧出海内购规模以“一年翻三倍”的速度增长;中国开源大模型在海外调用量一度超过美国;跨境电商AI应用、出海品牌的本地化营销Agent需求呈井喷之势。他们需要的不是一次性大单,而是一个可持续、合规、本地化的数据供应伙伴。艺恩海外业务首次千万级突破,只是这条通道刚刚打通的信号。
第三个机会是多模态爆发带来的“垂类高质量数据集”稀缺性。Sora 2、Veo 3、Kling 2.0等视频生成模型的竞赛,使视频 - 文本对齐数据、帧级caption、剧情结构标注成为真正的“战略物资”。Epoch AI的“数据墙”预言表明,通用文本将很快耗尽,未来十年的竞争将聚焦于垂类高质量数据集领域,“影视综、代言人、社媒情绪、品牌合作、剧综软广”恰好是艺恩长期积累的四大领域。
然而,必须清醒地认识到,机会并不等同于胜利。艺恩体量仍小,产品化比例仍在爬坡,数据产品业务的127.68%增速需要在更高基数上再次证明;海外千万级突破只是起点而非终点;无形资产入表的会计动作,也需要相应的审计、评估、估值方法论跟进。产业链不会奖励“站在风口上的人”,只会青睐“在风来之前就把房子盖好的人”。
结语:被低估的供应链卡位者,还是被新秩序重塑的老玩家
回到文章开头的会议室。凌晨两点,数据负责人删除了那三成“来源不清”的数据,开始讨论替代方案。有人说需要真正“干净”的数据,有人说需要更垂直、更具中国语境的数据,还有人表示需要一个能陪伴公司发展到下一个版本的“数据伙伴”。
这些声音共同勾勒出2026年中国AI数据供应链的需求曲线,指向一批过去被低估的玩家——他们既非巨头,也非网红创业公司,而是在某一垂直领域默默积累十几年结构化数据的“供应链卡位者”。艺恩数据便是其中之一。其坐标独特:横跨产品层、渠道层、应用层,覆盖三模态四领域,资产化、产品化、出海化三条曲线同时上扬。
它会成为那个“被低估的供应链卡位者”,还是“被产业链新秩序重塑的老玩家”?这是2026年留给资本市场的一道开放题。答案不会出现在一份年报中,而将在未来三到五年的每一次订单、每一次复购、每一次资产评估中逐渐揭晓。
但有一点是确定的:大模型的故事已进入第三季,而真正决定胜负的“原材料”问题,才刚刚翻开第一页。